ISO-8859-2 speciális karakterek
Beküldte pzoli - 2011, május 26 - 5:50du
Külső hivatkozás a forrásra: Letter Database.
8859-2
0xA0
 UTF-8 (c2, a0) Â |
name: NO-BREAK SPACE |
| old name: |
|
| Adobe glyph name: space | |
| mnemonic name(s): <NS> | |
| HTML 4 mnemonic name: | |
| category: Zs (Separator, Space) | |
| combining: 0 | |
| decomposition info: <noBreak> 0020 | |
| comment: | |
| found in charsets: 8859-1 (A0); 8859-10 (A0); 8859-13 (A0); 8859-14 (A0); 8859-15 (A0); 8859-2 (A0); 8859-3 (A0); 8859-4 (A0); 8859-5 (A0); 8859-6 (A0); 8859-7 (A0); 8859-8 (A0); 8859-9 (A0); CP1250 (A0); CP1251 (A0); CP1252 (A0); CP1253 (A0); CP1254 (A0); CP1255 (A0); CP1256 (A0); CP1257 (A0); CP1258 (A0); CP437 (FF); CP737 (FF); CP775 (FF); CP850 (FF); CP852 (FF); CP855 (FF); CP857 (FF); CP860 (FF); CP861 (FF); CP862 (FF); CP863 (FF); CP864 (A0); CP865 (FF); CP866 (FF); CP869 (FF); CP874 (A0); ROMAN (CA); CP1116 (FF); CP1122 (41); CP878 (9A); SAMI_WIN (A0); SAMI_MAC (CA); CENTEURO (CA); 8859-16 (A0); |
|
| found in languages: | |
| used in romanization of: |
0xA1
 UTF-8 (c4, 84) � |
name: LATIN CAPITAL LETTER A WITH OGONEK |
| old name: |
|
| Adobe glyph name: Aogonek | |
| mnemonic name(s): <A;> | |
| HTML 4 mnemonic name: | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 0041 0328 | |
| comment: | |
| found in charsets: 8859-10 (A1); 8859-13 (C0); 8859-2 (A1); 8859-4 (A1); CP1250 (A5); CP1257 (C0); CP775 (B5); CP852 (A4); CENTEURO (84); 8859-16 (A1); |
|
| found in languages: lt [Lithuanian]; pl [Polish]; sla [Kashubian]; | |
| used in romanization of: | |
| lowercase: 0105 |
0xA2
 UTF-8 (cb, 98) � |
name: BREVE |
| old name: |
|
| Adobe glyph name: breve | |
| mnemonic name(s): <'(> | |
| HTML 4 mnemonic name: | |
| category: Sk (Symbol, Modifier) | |
| combining: 0 | |
| decomposition info: <compat> 0020 0306 | |
| comment: | |
| found in charsets: 8859-2 (A2); 8859-3 (A2); CP1250 (A2); CP852 (F4); ROMAN (F9); | |
| found in languages: | |
| used in romanization of: |
0xA3
 UTF-8 (c5, 81) � |
name: LATIN CAPITAL LETTER L WITH STROKE |
| old name: |
|
| Adobe glyph name: Lslash | |
| mnemonic name(s): <L//> | |
| HTML 4 mnemonic name: | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| comment: | |
| found in charsets: 8859-13 (D9); 8859-2 (A3); CP1250 (A3); CP1257 (D9); CP775 (AD); CP852 (9D); CENTEURO (FC); 8859-16 (A3); | |
| found in languages: pl [Polish]; sorb1 [Lower Sorbian]; sorb2 [Upper Sorbian]; sla [Kashubian]; be [Belarusian]; | |
| used in romanization of: | |
| lowercase: 0142 |
0xA4
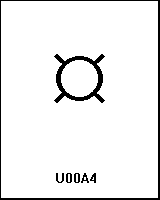 UTF-8 (c2, a4) ¤ |
name: CURRENCY SIGN |
| old name: | |
| Adobe glyph name: currency | |
| mnemonic name(s): <Cu> | |
| HTML 4 mnemonic name:¤ | |
| category: Sc (Symbol, Currency) | |
| combining: 0 | |
| comment: | |
| found in charsets: 8859-1 (A4); 8859-13 (A4); 8859-2 (A4); 8859-3 (A4); 8859-4 (A4); 8859-6 (A4); 8859-8 (A4); 8859-9 (A4); CP1250 (A4); CP1251 (A4); CP1252 (A4); CP1253 (A4); CP1254 (A4); CP1256 (A4); CP1257 (A4); CP1258 (A4); CP775 (9F); CP850 (CF); CP852 (CF); CP855 (CF); CP857 (CF); CP863 (98); CP864 (A4); CP865 (AF); CP866 (FD); ROMAN (DB); CP1116 (CF); CP1122 (5A); SAMI_WIN (A4); VENTURA_INT (9E); |
|
| found in languages: | |
| used in romanization of: |
0xA5
 UTF-8 (c4, bd) Ä˝ |
name: LATIN CAPITAL LETTER L WITH CARON |
| old name: |
|
| Adobe glyph name: Lcaron | |
| mnemonic name(s): <L<> | |
| HTML 4 mnemonic name: | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 004C 030C | |
| comment: | |
| found in charsets: 8859-2 (A5); CP1250 (BC); CP852 (95); CENTEURO (BB); | |
| found in languages: sk [Slovak]; | |
| used in romanization of: | |
| lowercase: 013E |
0xA6
 UTF-8 (c5, 9a) � |
name: LATIN CAPITAL LETTER S WITH ACUTE |
| old name: |
|
| Adobe glyph name: Sacute | |
| mnemonic name(s): <S'> | |
| HTML 4 mnemonic name: | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 0053 0301 | |
| comment: | |
| found in charsets: 8859-13 (DA); 8859-2 (A6); CP1250 (8C); CP1257 (DA); CP775 (97); CP852 (97); CENTEURO (E5); 8859-16 (D7); | |
| found in languages: pl [Polish]; sorb1 [Lower Sorbian]; sla [Kashubian]; be [Belarusian]; | |
| used in romanization of: ne_r [Nepali (devanagari)]; | |
| lowercase: 015B |
0xA7
 UTF-8 (c2, a7) § |
name: SECTION SIGN |
| old name: | |
| Adobe glyph name: section | |
| mnemonic name(s): <SE> | |
| HTML 4 mnemonic name:§ | |
| category: So (Symbol, Other) | |
| combining: 0 | |
| comment: | |
| found in charsets: 8859-1 (A7); 8859-10 (A7); 8859-13 (A7); 8859-14 (A7); 8859-15 (A7); 8859-2 (A7); 8859-3 (A7); 8859-4 (A7); 8859-5 (FD); 8859-7 (A7); 8859-8 (A7); 8859-9 (A7); CP1250 (A7); CP1251 (A7); CP1252 (A7); CP1253 (A7); CP1254 (A7); CP1255 (A7); CP1256 (A7); CP1257 (A7); CP1258 (A7); CP775 (F5); CP850 (F5); CP852 (F5); CP855 (FD); CP857 (F5); CP863 (8F); CP869 (F5); ROMAN (A4); CP1116 (F5); CP1122 (4A); SAMI_WIN (A7); SAMI_MAC (A4); CENTEURO (A4); 8859-16 (A7); VENTURA_INT (B9); |
|
| found in languages: | |
| used in romanization of: |
0xA8
 UTF-8 (c2, a8) ¨ |
name: DIAERESIS |
| old name: |
|
| Adobe glyph name: dieresis | |
| mnemonic name(s): <':> | |
| HTML 4 mnemonic name:¨ | |
| category: Sk (Symbol, Modifier) | |
| combining: 0 | |
| decomposition info: <compat> 0020 0308 | |
| comment: | |
| found in charsets: 8859-1 (A8); 8859-2 (A8); 8859-3 (A8); 8859-4 (A8); 8859-7 (A8); 8859-8 (A8); 8859-9 (A8); CP1250 (A8); CP1252 (A8); CP1253 (A8); CP1254 (A8); CP1255 (A8); CP1256 (A8); CP1257 (8D); CP1258 (A8); CP850 (F9); CP852 (F9); CP857 (F9); CP863 (A4); CP869 (F9); ROMAN (AC); CP1116 (F9); CP1122 (BD); SAMI_WIN (A8); SAMI_MAC (AC); CENTEURO (AC); |
|
| found in languages: | |
| used in romanization of: |
0xA9
 UTF-8 (c5, a0) Ĺ |
name: LATIN CAPITAL LETTER S WITH CARON |
| old name: |
|
| Adobe glyph name: Scaron | |
| mnemonic name(s): <S<> | |
| HTML 4 mnemonic name:Š | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 0053 030C | |
| comment: | |
| found in charsets: 8859-10 (AA); 8859-13 (D0); 8859-15 (A6); 8859-2 (A9); 8859-4 (A9); CP1250 (8A); CP1252 (8A); CP1254 (8A); CP1257 (D0); CP775 (BE); CP852 (E6); CP1116 (D1); CP1122 (AC); SAMI_WIN (8A); SAMI_MAC (B4); CENTEURO (E1); 8859-16 (A6); VENTURA_INT (D3); |
|
| found in languages: bs [Bosnian]; cs [Czech]; et [Estonian]; fi [Finnish]; hr [Croatian]; livo [Livonian]; lt [Lithuanian]; lv [Latvian]; sami1 [Inari Sámi]; sami2 [North Sámi]; sami4 [Skolt Sámi]; sk [Slovak]; sl [Slovenian]; sorb1 [Lower Sorbian]; sorb2 [Upper Sorbian]; tn [Tswana]; be [Belarusian]; nso [Northern Sotho]; sr [Serbian]; |
|
| used in romanization of: be_r [Belarusian (cyrillic)]; bg_r [Bulgarian (cyrillic)]; mk_r [Macedonian (cyrillic)]; ru_r [Russian (cyrillic)]; sr_r [Serbian (cyrillic)]; |
|
| lowercase: 0161 |
0xAA
 UTF-8 (c5, 9e) � |
name: LATIN CAPITAL LETTER S WITH CEDILLA |
| old name: |
|
| Adobe glyph name: Scommaaccent | |
| mnemonic name(s): <S,> | |
| HTML 4 mnemonic name: | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 0053 0327 | |
| comment: * | |
| Note: Please see note 1 |
|
| found in charsets: 8859-2 (AA); 8859-3 (AA); 8859-9 (DE); CP1250 (AA); CP1254 (DE); CP852 (B8); CP857 (9E); | |
| found in languages: az [Azerbaijani]; ku [Kurdish]; tk [Turkmen]; tr [Turkish]; tt [Tatar]; | |
| used in romanization of: ar_r [Arabic (perso-arabic)]; fa_r [Persian (perso-arabic)]; ps_r [Pashto (perso-arabic)]; | |
| lowercase: 015F |
0xAB
 UTF-8 (c5, a4) Ť |
name: LATIN CAPITAL LETTER T WITH CARON |
| old name: |
|
| Adobe glyph name: Tcaron | |
| mnemonic name(s): <T<> | |
| HTML 4 mnemonic name: | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 0054 030C | |
| comment: | |
| found in charsets: 8859-2 (AB); CP1250 (8D); CP852 (9B); CENTEURO (E8); | |
| found in languages: cs [Czech]; sk [Slovak]; | |
| used in romanization of: | |
| lowercase: 0165 |
0xAC
 UTF-8 (c5, b9) Ĺš |
name: LATIN CAPITAL LETTER Z WITH ACUTE |
| old name: |
|
| Adobe glyph name: Zacute | |
| mnemonic name(s): <Z'> | |
| HTML 4 mnemonic name: | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 005A 0301 | |
| comment: | |
| found in charsets: 8859-13 (CA); 8859-2 (AC); CP1250 (8F); CP1257 (CA); CP775 (8D); CP852 (8D); CENTEURO (8F); 8859-16 (AC); | |
| found in languages: pl [Polish]; sorb1 [Lower Sorbian]; sorb2 [Upper Sorbian]; sla [Kashubian]; be [Belarusian]; | |
| used in romanization of: | |
| lowercase: 017A |
0xAD
 UTF-8 (c2, ad) Â |
name: SOFT HYPHEN |
| old name: | |
| Adobe glyph name: hyphen | |
| mnemonic name(s): <--> | |
| HTML 4 mnemonic name:­ | |
| category: Cf (Other, Format) | |
| combining: 0 | |
| comment: | |
| found in charsets: 8859-1 (AD); 8859-10 (AD); 8859-13 (AD); 8859-14 (AD); 8859-15 (AD); 8859-2 (AD); 8859-3 (AD); 8859-4 (AD); 8859-5 (AD); 8859-6 (AD); 8859-7 (AD); 8859-8 (AD); 8859-9 (AD); CP1250 (AD); CP1251 (AD); CP1252 (AD); CP1253 (AD); CP1254 (AD); CP1255 (AD); CP1256 (AD); CP1257 (AD); CP1258 (AD); CP775 (F0); CP850 (F0); CP852 (F0); CP855 (F0); CP857 (F0); CP864 (A1); CP869 (F0); CP1116 (F0); CP1122 (CA); SAMI_WIN (AD); 8859-16 (AD); |
|
| found in languages: | |
| used in romanization of: |
0xAE
 UTF-8 (c5, bd) Ĺ˝ |
name: LATIN CAPITAL LETTER Z WITH CARON |
| old name: |
|
| Adobe glyph name: Zcaron | |
| mnemonic name(s): <Z<> | |
| HTML 4 mnemonic name: | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 005A 030C | |
| comment: | |
| found in charsets: 8859-10 (AC); 8859-13 (DE); 8859-15 (B4); 8859-2 (AE); 8859-4 (AE); CP1250 (8E); CP1252 (8E); CP1257 (DE); CP775 (CF); CP852 (A6); CP1116 (E8); CP1122 (AE); SAMI_WIN (BE); SAMI_MAC (B7); CENTEURO (EB); 8859-16 (B4); |
|
| found in languages: bs [Bosnian]; cs [Czech]; et [Estonian]; fi [Finnish]; hr [Croatian]; livo [Livonian]; lt [Lithuanian]; lv [Latvian]; sami1 [Inari Sámi]; sami2 [North Sámi]; sami4 [Skolt Sámi]; sk [Slovak]; sl [Slovenian]; sorb1 [Lower Sorbian]; sorb2 [Upper Sorbian]; tk [Turkmen]; be [Belarusian]; sr [Serbian]; |
|
| used in romanization of: be_r [Belarusian (cyrillic)]; bg_r [Bulgarian (cyrillic)]; mk_r [Macedonian (cyrillic)]; ru_r [Russian (cyrillic)]; sr_r [Serbian (cyrillic)]; |
|
| lowercase: 017E |
0xAF
 UTF-8 (c5, bb) Ĺť |
name: LATIN CAPITAL LETTER Z WITH DOT ABOVE |
| old name: |
|
| Adobe glyph name: Zdotaccent | |
| mnemonic name(s): <Z.> | |
| HTML 4 mnemonic name: | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 005A 0307 | |
| comment: | |
| found in charsets: 8859-13 (DD); 8859-2 (AF); 8859-3 (AF); CP1250 (AF); CP1257 (DD); CP775 (A3); CP852 (BD); CENTEURO (FB); 8859-16 (AF); | |
| found in languages: mt [Maltese]; pl [Polish]; sla [Kashubian]; | |
| used in romanization of: | |
| lowercase: 017C |
0xB0
 UTF-8 (c2, b0) ° |
name: DEGREE SIGN |
| old name: | |
| Adobe glyph name: degree | |
| mnemonic name(s): <DG> | |
| HTML 4 mnemonic name:° | |
| category: So (Symbol, Other) | |
| combining: 0 | |
| comment: | |
| found in charsets: 8859-1 (B0); 8859-10 (B0); 8859-13 (B0); 8859-15 (B0); 8859-2 (B0); 8859-3 (B0); 8859-4 (B0); 8859-7 (B0); 8859-8 (B0); 8859-9 (B0); CP1250 (B0); CP1251 (B0); CP1252 (B0); CP1253 (B0); CP1254 (B0); CP1255 (B0); CP1256 (B0); CP1257 (B0); CP1258 (B0); CP437 (F8); CP737 (F8); CP775 (F8); CP850 (F8); CP852 (F8); CP857 (F8); CP860 (F8); CP861 (F8); CP862 (F8); CP863 (F8); CP864 (80); CP865 (F8); CP866 (F8); CP869 (F8); ROMAN (A1); CP1116 (F8); CP1122 (90); CP878 (9C); SAMI_WIN (B0); SAMI_MAC (A1); CENTEURO (A1); 8859-16 (B0); VENTURA_INT (C6); VENTURA_SYM (90); |
|
| found in languages: | |
| used in romanization of: |
0xB1
 UTF-8 (c4, 85) � |
name: LATIN SMALL LETTER A WITH OGONEK |
| old name: |
|
| Adobe glyph name: aogonek | |
| mnemonic name(s): <a;> | |
| HTML 4 mnemonic name: | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 0061 0328 | |
| comment: | |
| found in charsets: 8859-10 (B1); 8859-13 (E0); 8859-2 (B1); 8859-4 (B1); CP1250 (B9); CP1257 (E0); CP775 (D0); CP852 (A5); CENTEURO (88); 8859-16 (A2); |
|
| found in languages: lt [Lithuanian]; pl [Polish]; sla [Kashubian]; | |
| used in romanization of: | |
| uppercase: 0104 |
0xB2
 UTF-8 (cb, 9b) � |
name: OGONEK |
| old name: |
|
| Adobe glyph name: ogonek | |
| mnemonic name(s): <';> | |
| HTML 4 mnemonic name: | |
| category: Sk (Symbol, Modifier) | |
| combining: 0 | |
| decomposition info: <compat> 0020 0328 | |
| comment: | |
| found in charsets: 8859-2 (B2); 8859-4 (B2); CP1250 (B2); CP1257 (9E); CP852 (F2); ROMAN (FE); | |
| found in languages: | |
| used in romanization of: |
0xB3
 UTF-8 (c5, 82) � |
name: LATIN SMALL LETTER L WITH STROKE |
| old name: |
|
| Adobe glyph name: lslash | |
| mnemonic name(s): <l//> | |
| HTML 4 mnemonic name: | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| comment: | |
| found in charsets: 8859-13 (F9); 8859-2 (B3); CP1250 (B3); CP1257 (F9); CP775 (88); CP852 (88); CENTEURO (B8); 8859-16 (B3); | |
| found in languages: pl [Polish]; sorb1 [Lower Sorbian]; sorb2 [Upper Sorbian]; sla [Kashubian]; be [Belarusian]; | |
| used in romanization of: | |
| uppercase: 0141 |
0xB4
 UTF-8 (c2, b4) ´ |
name: ACUTE ACCENT |
| old name: |
|
| Adobe glyph name: acute | |
| mnemonic name(s): <''> | |
| HTML 4 mnemonic name:´ | |
| category: Sk (Symbol, Modifier) | |
| combining: 0 | |
| decomposition info: <compat> 0020 0301 | |
| comment: | |
| found in charsets: 8859-1 (B4); 8859-2 (B4); 8859-3 (B4); 8859-4 (B4); 8859-8 (B4); 8859-9 (B4); CP1250 (B4); CP1252 (B4); CP1254 (B4); CP1255 (B4); CP1256 (B4); CP1257 (B4); CP1258 (B4); CP850 (EF); CP852 (EF); CP857 (EF); CP863 (A1); ROMAN (AB); CP1116 (EF); CP1122 (BE); SAMI_WIN (B4); SAMI_MAC (AB); |
|
| found in languages: | |
| used in romanization of: |
0xB5
 UTF-8 (c4, be) Äž |
name: LATIN SMALL LETTER L WITH CARON |
| old name: |
|
| Adobe glyph name: lcaron | |
| mnemonic name(s): <l<> | |
| HTML 4 mnemonic name: | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 006C 030C | |
| comment: | |
| found in charsets: 8859-2 (B5); CP1250 (BE); CP852 (96); CENTEURO (BC); | |
| found in languages: sk [Slovak]; | |
| used in romanization of: | |
| uppercase: 013D |
0xB6
 UTF-8 (c5, 9b) � |
name: LATIN SMALL LETTER S WITH ACUTE |
| old name: |
|
| Adobe glyph name: sacute | |
| mnemonic name(s): <s'> | |
| HTML 4 mnemonic name: | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 0073 0301 | |
| comment: | |
| found in charsets: 8859-13 (FA); 8859-2 (B6); CP1250 (9C); CP1257 (FA); CP775 (98); CP852 (98); CENTEURO (E6); 8859-16 (F7); | |
| found in languages: pl [Polish]; sorb1 [Lower Sorbian]; sla [Kashubian]; be [Belarusian]; | |
| used in romanization of: ne_r [Nepali (devanagari)]; | |
| uppercase: 015A |
0xB7
 UTF-8 (cb, 87) � |
name: CARON |
| old name: |
|
| Adobe glyph name: caron | |
| mnemonic name(s): <'<> | |
| HTML 4 mnemonic name: | |
| category: Lm (Letter, Modifier) | |
| combining: 0 | |
| comment: Mandarin Chinese third tone | |
| found in charsets: 8859-2 (B7); 8859-4 (B7); CP1250 (A1); CP1257 (8E); CP852 (F3); ROMAN (FF); CENTEURO (FF); | |
| found in languages: | |
| used in romanization of: |
0xB8
 UTF-8 (c2, b8) ¸ |
name: CEDILLA |
| old name: |
|
| Adobe glyph name: cedilla | |
| mnemonic name(s): <',> | |
| HTML 4 mnemonic name:¸ | |
| category: Sk (Symbol, Modifier) | |
| combining: 0 | |
| decomposition info: <compat> 0020 0327 | |
| comment: | |
| found in charsets: 8859-1 (B8); 8859-2 (B8); 8859-3 (B8); 8859-4 (B8); 8859-8 (B8); 8859-9 (B8); CP1250 (B8); CP1252 (B8); CP1254 (B8); CP1255 (B8); CP1256 (B8); CP1257 (8F); CP1258 (B8); CP850 (F7); CP852 (F7); CP857 (F7); CP863 (A5); ROMAN (FC); CP1116 (F7); CP1122 (9D); |
|
| found in languages: | |
| used in romanization of: |
0xB9
 UTF-8 (c5, a1) ĹĄ |
name: LATIN SMALL LETTER S WITH CARON |
| old name: |
|
| Adobe glyph name: scaron | |
| mnemonic name(s): <s<> | |
| HTML 4 mnemonic name:š | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 0073 030C | |
| comment: | |
| found in charsets: 8859-10 (BA); 8859-13 (F0); 8859-15 (A8); 8859-2 (B9); 8859-4 (B9); CP1250 (9A); CP1252 (9A); CP1254 (9A); CP1257 (F0); CP775 (D5); CP852 (E7); CP1116 (D0); CP1122 (8C); SAMI_WIN (9A); SAMI_MAC (BB); CENTEURO (E4); 8859-16 (A8); VENTURA_INT (D4); |
|
| found in languages: bs [Bosnian]; cs [Czech]; et [Estonian]; fi [Finnish]; hr [Croatian]; livo [Livonian]; lt [Lithuanian]; lv [Latvian]; sami1 [Inari Sámi]; sami2 [North Sámi]; sami4 [Skolt Sámi]; sk [Slovak]; sl [Slovenian]; sorb1 [Lower Sorbian]; sorb2 [Upper Sorbian]; tn [Tswana]; be [Belarusian]; nso [Northern Sotho]; sr [Serbian]; |
|
| used in romanization of: be_r [Belarusian (cyrillic)]; bg_r [Bulgarian (cyrillic)]; mk_r [Macedonian (cyrillic)]; ru_r [Russian (cyrillic)]; sr_r [Serbian (cyrillic)]; |
|
| uppercase: 0160 |
0xBA
 UTF-8 (c5, 9f) � |
name: LATIN SMALL LETTER S WITH CEDILLA |
| old name: |
|
| Adobe glyph name: scommaaccent | |
| mnemonic name(s): <s,> | |
| HTML 4 mnemonic name: | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 0073 0327 | |
| comment: * | |
| found in charsets: 8859-2 (BA); 8859-3 (BA); 8859-9 (FE); CP1250 (BA); CP1254 (FE); CP852 (AD); CP857 (9F); | |
| found in languages: az [Azerbaijani]; ku [Kurdish]; tk [Turkmen]; tr [Turkish]; tt [Tatar]; | |
| used in romanization of: ar_r [Arabic (perso-arabic)]; fa_r [Persian (perso-arabic)]; ps_r [Pashto (perso-arabic)]; | |
| uppercase: 015E |
0xBB
 UTF-8 (c5, a5) ĹĽ |
name: LATIN SMALL LETTER T WITH CARON |
| old name: |
|
| Adobe glyph name: tcaron | |
| mnemonic name(s): <t<> | |
| HTML 4 mnemonic name: | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 0074 030C | |
| comment: | |
| found in charsets: 8859-2 (BB); CP1250 (9D); CP852 (9C); CENTEURO (E9); | |
| found in languages: cs [Czech]; sk [Slovak]; | |
| used in romanization of: | |
| uppercase: 0164 |
0xBC
 UTF-8 (c5, ba) Ĺş |
name: LATIN SMALL LETTER Z WITH ACUTE |
| old name: |
|
| Adobe glyph name: zacute | |
| mnemonic name(s): <z'> | |
| HTML 4 mnemonic name: | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 007A 0301 | |
| comment: | |
| found in charsets: 8859-13 (EA); 8859-2 (BC); CP1250 (9F); CP1257 (EA); CP775 (A5); CP852 (AB); CENTEURO (90); 8859-16 (AE); | |
| found in languages: pl [Polish]; sorb1 [Lower Sorbian]; sorb2 [Upper Sorbian]; sla [Kashubian]; be [Belarusian]; | |
| used in romanization of: | |
| uppercase: 0179 |
0xBD
 UTF-8 (cb, 9d) � |
name: DOUBLE ACUTE ACCENT |
| old name: |
|
| Adobe glyph name: hungarumlaut | |
| mnemonic name(s): <'"> | |
| HTML 4 mnemonic name: | |
| category: Sk (Symbol, Modifier) | |
| combining: 0 | |
| decomposition info: <compat> 0020 030B | |
| comment: | |
| found in charsets: 8859-2 (BD); CP1250 (BD); CP852 (F1); ROMAN (FD); | |
| found in languages: | |
| used in romanization of: |
0xBE
 UTF-8 (c5, be) Ĺž |
name: LATIN SMALL LETTER Z WITH CARON |
| old name: |
|
| Adobe glyph name: zcaron | |
| mnemonic name(s): <z<> | |
| HTML 4 mnemonic name: | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 007A 030C | |
| comment: | |
| found in charsets: 8859-10 (BC); 8859-13 (FE); 8859-15 (B8); 8859-2 (BE); 8859-4 (BE); CP1250 (9E); CP1252 (9E); CP1257 (FE); CP775 (D8); CP852 (A7); CP1116 (E7); CP1122 (8E); SAMI_WIN (BF); SAMI_MAC (BD); CENTEURO (EC); 8859-16 (B8); |
|
| found in languages: bs [Bosnian]; cs [Czech]; et [Estonian]; fi [Finnish]; hr [Croatian]; livo [Livonian]; lt [Lithuanian]; lv [Latvian]; sami1 [Inari Sámi]; sami2 [North Sámi]; sami4 [Skolt Sámi]; sk [Slovak]; sl [Slovenian]; sorb1 [Lower Sorbian]; sorb2 [Upper Sorbian]; tk [Turkmen]; be [Belarusian]; sr [Serbian]; |
|
| used in romanization of: be_r [Belarusian (cyrillic)]; bg_r [Bulgarian (cyrillic)]; mk_r [Macedonian (cyrillic)]; ru_r [Russian (cyrillic)]; sr_r [Serbian (cyrillic)]; |
|
| uppercase: 017D |
0xBF
 UTF-8 (c5, bc) Ĺź |
name: LATIN SMALL LETTER Z WITH DOT ABOVE |
| old name: |
|
| Adobe glyph name: zdotaccent | |
| mnemonic name(s): <z.> | |
| HTML 4 mnemonic name: | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 007A 0307 | |
| comment: | |
| found in charsets: 8859-13 (FD); 8859-2 (BF); 8859-3 (BF); CP1250 (BF); CP1257 (FD); CP775 (A4); CP852 (BE); CENTEURO (FD); 8859-16 (BF); | |
| found in languages: mt [Maltese]; pl [Polish]; sla [Kashubian]; | |
| used in romanization of: | |
| uppercase: 017B |
0xC0
 UTF-8 (c5, 94) � |
name: LATIN CAPITAL LETTER R WITH ACUTE |
| old name: |
|
| Adobe glyph name: Racute | |
| mnemonic name(s): <R'> | |
| HTML 4 mnemonic name: | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 0052 0301 | |
| comment: | |
| found in charsets: 8859-2 (C0); CP1250 (C0); CP852 (E8); CENTEURO (D9); | |
| found in languages: sk [Slovak]; sorb1 [Lower Sorbian]; | |
| used in romanization of: | |
| lowercase: 0155 |
0xC1
 UTF-8 (c3, 81) � |
name: LATIN CAPITAL LETTER A WITH ACUTE |
| old name: |
|
| Adobe glyph name: Aacute | |
| mnemonic name(s): <A'> | |
| HTML 4 mnemonic name:Á | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 0041 0301 | |
| comment: | |
| found in charsets: 8859-1 (C1); 8859-10 (C1); 8859-14 (C1); 8859-15 (C1); 8859-2 (C1); 8859-3 (C1); 8859-4 (C1); 8859-9 (C1); CP1250 (C1); CP1252 (C1); CP1254 (C1); CP1258 (C1); CP850 (B5); CP852 (B5); CP857 (B5); CP860 (86); CP861 (A4); ROMAN (E7); CP1116 (B5); CP1122 (65); SAMI_WIN (C1); SAMI_MAC (E7); CENTEURO (E7); 8859-16 (C1); VENTURA_INT (C7); |
|
| found in languages: cs [Czech]; cy [Welsh]; da [Danish]; es [Spanish]; fo [Faroese]; ga [Irish]; gd [Gaelic (Scots)]; gl [Galician]; gn [Guaraní]; hu [Hungarian]; is [Icelandic]; it [Italian]; kl [Greenlandic]; mg [Malagasy]; nl [Dutch]; oc [Occitan]; pt [Portuguese]; sami1 [Inari Sámi]; sami2 [North Sámi]; sami3 [Lule Sámi]; sk [Slovak]; sv [Swedish]; tl [Pilipino (Tagalog)]; vi [Vietnamese]; yo [Yoruba]; |
|
| used in romanization of: ar_r [Arabic (perso-arabic)]; el_r [Greek (greek)]; fa_r [Persian (perso-arabic)]; km_r [Khmer (khmer)]; zh_r [Chinese (sino-japanese)]; |
|
| lowercase: 00E1 |
0xC2
 UTF-8 (c3, 82) � |
name: LATIN CAPITAL LETTER A WITH CIRCUMFLEX |
| old name: |
|
| Adobe glyph name: Acircumflex | |
| mnemonic name(s): <A/>> | |
| HTML 4 mnemonic name:Â | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 0041 0302 | |
| comment: | |
| found in charsets: 8859-1 (C2); 8859-10 (C2); 8859-14 (C2); 8859-15 (C2); 8859-2 (C2); 8859-3 (C2); 8859-4 (C2); 8859-9 (C2); CP1250 (C2); CP1252 (C2); CP1254 (C2); CP1258 (C2); CP850 (B6); CP852 (B6); CP857 (B6); CP860 (8F); CP863 (84); ROMAN (E5); CP1116 (B6); CP1122 (62); SAMI_WIN (C2); SAMI_MAC (E5); 8859-16 (C2); VENTURA_INT (C8); |
|
| found in languages: br [Breton]; ch [Chamorro]; cy [Welsh]; fr [French]; fy [Frisian]; kl [Greenlandic]; lb [Luxembourgian]; nl [Dutch]; pt [Portuguese]; ro [Romanian]; sami1 [Inari Sámi]; sami4 [Skolt Sámi]; tl [Pilipino (Tagalog)]; tr [Turkish]; vi [Vietnamese]; yo [Yoruba]; wa [Walloon]; |
|
| used in romanization of: ar_r [Arabic (perso-arabic)]; km_r [Khmer (khmer)]; | |
| lowercase: 00E2 |
0xC3
 UTF-8 (c4, 82) � |
name: LATIN CAPITAL LETTER A WITH BREVE |
| old name: |
|
| Adobe glyph name: Abreve | |
| mnemonic name(s): <A(> | |
| HTML 4 mnemonic name: | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 0041 0306 | |
| comment: | |
| found in charsets: 8859-2 (C3); CP1250 (C3); CP1258 (C3); CP852 (C6); 8859-16 (C3); | |
| found in languages: ro [Romanian]; vi [Vietnamese]; | |
| used in romanization of: km_r [Khmer (khmer)]; | |
| lowercase: 0103 |
0xC4
 UTF-8 (c3, 84) � |
name: LATIN CAPITAL LETTER A WITH DIAERESIS |
| old name: |
|
| Adobe glyph name: Adieresis | |
| mnemonic name(s): <A:> | |
| HTML 4 mnemonic name:Ä | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 0041 0308 | |
| comment: | |
| found in charsets: 8859-1 (C4); 8859-10 (C4); 8859-13 (C4); 8859-14 (C4); 8859-15 (C4); 8859-2 (C4); 8859-3 (C4); 8859-4 (C4); 8859-9 (C4); CP1250 (C4); CP1252 (C4); CP1254 (C4); CP1257 (C4); CP1258 (C4); CP437 (8E); CP775 (8E); CP850 (8E); CP852 (8E); CP857 (8E); CP861 (8E); CP865 (8E); ROMAN (80); CP1116 (8E); CP1122 (7B); SAMI_WIN (C4); SAMI_MAC (80); CENTEURO (80); 8859-16 (C4); VENTURA_INT (8E); |
|
| found in languages: az [Azerbaijani]; cy [Welsh]; de [German]; et [Estonian]; fi [Finnish]; fy [Frisian]; lb [Luxembourgian]; livo [Livonian]; nl [Dutch]; sami1 [Inari Sámi]; sami3 [Lule Sámi]; sami4 [Skolt Sámi]; sami5 [South Sámi]; sk [Slovak]; sl [Slovenian]; sv [Swedish]; tk [Turkmen]; yap [Yapese]; dink [Dinka]; |
|
| used in romanization of: kk_r [Kazakh (cyrillic)]; tk_r [Turkmen (cyrillic)]; | |
| lowercase: 00E4 |
0xC5
 UTF-8 (c4, b9) Äš |
name: LATIN CAPITAL LETTER L WITH ACUTE |
| old name: |
|
| Adobe glyph name: Lacute | |
| mnemonic name(s): <L'> | |
| HTML 4 mnemonic name: | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 004C 0301 | |
| comment: | |
| found in charsets: 8859-2 (C5); CP1250 (C5); CP852 (91); CENTEURO (BD); | |
| found in languages: sk [Slovak]; | |
| used in romanization of: | |
| lowercase: 013A |
0xC6
 UTF-8 (c4, 86) � |
name: LATIN CAPITAL LETTER C WITH ACUTE |
| old name: |
|
| Adobe glyph name: Cacute | |
| mnemonic name(s): <C'> | |
| HTML 4 mnemonic name: | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 0043 0301 | |
| comment: | |
| found in charsets: 8859-13 (C3); 8859-2 (C6); CP1250 (C6); CP1257 (C3); CP775 (80); CP852 (8F); CENTEURO (8C); 8859-16 (C5); | |
| found in languages: bs [Bosnian]; hr [Croatian]; pl [Polish]; sl [Slovenian]; sorb1 [Lower Sorbian]; sorb2 [Upper Sorbian]; sla [Kashubian]; be [Belarusian]; sr [Serbian]; |
|
| used in romanization of: mk_r [Macedonian (cyrillic)]; sr_r [Serbian (cyrillic)]; | |
| lowercase: 0107 |
0xC7
 UTF-8 (c3, 87) � |
name: LATIN CAPITAL LETTER C WITH CEDILLA |
| old name: |
|
| Adobe glyph name: Ccedilla | |
| mnemonic name(s): <C,> | |
| HTML 4 mnemonic name:Ç | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 0043 0327 | |
| comment: | |
| found in charsets: 8859-1 (C7); 8859-14 (C7); 8859-15 (C7); 8859-2 (C7); 8859-3 (C7); 8859-9 (C7); CP1250 (C7); CP1252 (C7); CP1254 (C7); CP1258 (C7); CP437 (80); CP850 (80); CP852 (80); CP857 (80); CP860 (80); CP861 (80); CP863 (80); CP865 (80); ROMAN (82); CP1116 (80); CP1122 (68); SAMI_WIN (C7); SAMI_MAC (82); 8859-16 (C7); VENTURA_INT (80); |
|
| found in languages: az [Azerbaijani]; ku [Kurdish]; ca [Catalan]; en [English]; es [Spanish]; eu [Basque]; fr [French]; oc [Occitan]; pt [Portuguese]; sq [Albanian]; tk [Turkmen]; tr [Turkish]; tt [Tatar]; wa [Walloon]; |
|
| used in romanization of: ar_r [Arabic (perso-arabic)]; | |
| lowercase: 00E7 |
0xC8
 UTF-8 (c4, 8c) � |
name: LATIN CAPITAL LETTER C WITH CARON |
| old name: |
|
| Adobe glyph name: Ccaron | |
| mnemonic name(s): <C<> | |
| HTML 4 mnemonic name: | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 0043 030C | |
| comment: | |
| found in charsets: 8859-10 (C8); 8859-13 (C8); 8859-2 (C8); 8859-4 (C8); CP1250 (C8); CP1257 (C8); CP775 (B6); CP852 (AC); SAMI_WIN (82); SAMI_MAC (A2); CENTEURO (89); 8859-16 (B2); |
|
| found in languages: bs [Bosnian]; cs [Czech]; hr [Croatian]; lt [Lithuanian]; lv [Latvian]; sami1 [Inari Sámi]; sami2 [North Sámi]; sami4 [Skolt Sámi]; sk [Slovak]; sl [Slovenian]; sorb1 [Lower Sorbian]; sorb2 [Upper Sorbian]; be [Belarusian]; sr [Serbian]; |
|
| used in romanization of: be_r [Belarusian (cyrillic)]; bg_r [Bulgarian (cyrillic)]; mk_r [Macedonian (cyrillic)]; ru_r [Russian (cyrillic)]; sr_r [Serbian (cyrillic)]; |
|
| lowercase: 010D |
0xC9
 UTF-8 (c3, 89) � |
name: LATIN CAPITAL LETTER E WITH ACUTE |
| old name: |
|
| Adobe glyph name: Eacute | |
| mnemonic name(s): <E'> | |
| HTML 4 mnemonic name:É | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 0045 0301 | |
| comment: | |
| found in charsets: 8859-1 (C9); 8859-10 (C9); 8859-13 (C9); 8859-14 (C9); 8859-15 (C9); 8859-2 (C9); 8859-3 (C9); 8859-4 (C9); 8859-9 (C9); CP1250 (C9); CP1252 (C9); CP1254 (C9); CP1257 (C9); CP1258 (C9); CP437 (90); CP775 (90); CP850 (90); CP852 (90); CP857 (90); CP860 (90); CP861 (90); CP863 (90); CP865 (90); ROMAN (83); CP1116 (90); CP1122 (E0); SAMI_WIN (C9); SAMI_MAC (83); CENTEURO (83); 8859-16 (C9); VENTURA_INT (90); |
|
| found in languages: af [Afrikaans]; ku [Kurdish]; bi [Bislama]; ca [Catalan]; cs [Czech]; cy [Welsh]; da [Danish]; de [German]; es [Spanish]; fr [French]; fy [Frisian]; ga [Irish]; gd [Gaelic (Scots)]; gl [Galician]; gn [Guaraní]; hu [Hungarian]; id [Indonesian]; is [Icelandic]; it [Italian]; kl [Greenlandic]; lb [Luxembourgian]; nl [Dutch]; no [Norwegian]; oc [Occitan]; pt [Portuguese]; rm [(Rhaeto-)Romance]; sk [Slovak]; sv [Swedish]; tl [Pilipino (Tagalog)]; vi [Vietnamese]; wo [Wolof]; yo [Yoruba]; sla [Kashubian]; wa [Walloon]; |
|
| used in romanization of: ar_r [Arabic (perso-arabic)]; el_r [Greek (greek)]; he_r [Hebrew (hebrew)]; km_r [Khmer (khmer)]; lo_r [Laotian (laotian)]; zh_r [Chinese (sino-japanese)]; |
|
| lowercase: 00E9 |
0xCA
 UTF-8 (c4, 98) � |
name: LATIN CAPITAL LETTER E WITH OGONEK |
| old name: |
|
| Adobe glyph name: Eogonek | |
| mnemonic name(s): <E;> | |
| HTML 4 mnemonic name: | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 0045 0328 | |
| comment: | |
| found in charsets: 8859-10 (CA); 8859-13 (C6); 8859-2 (CA); 8859-4 (CA); CP1250 (CA); CP1257 (C6); CP775 (B7); CP852 (A8); CENTEURO (A2); 8859-16 (DD); |
|
| found in languages: lt [Lithuanian]; pl [Polish]; sla [Kashubian]; | |
| used in romanization of: | |
| lowercase: 0119 |
0xCB
 UTF-8 (c3, 8b) � |
name: LATIN CAPITAL LETTER E WITH DIAERESIS |
| old name: |
|
| Adobe glyph name: Edieresis | |
| mnemonic name(s): <E:> | |
| HTML 4 mnemonic name:Ë | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 0045 0308 | |
| comment: | |
| found in charsets: 8859-1 (CB); 8859-10 (CB); 8859-14 (CB); 8859-15 (CB); 8859-2 (CB); 8859-3 (CB); 8859-4 (CB); 8859-9 (CB); CP1250 (CB); CP1252 (CB); CP1254 (CB); CP1258 (CB); CP850 (D3); CP852 (D3); CP857 (D3); CP863 (94); ROMAN (E8); CP1116 (D3); CP1122 (73); SAMI_WIN (CB); SAMI_MAC (E8); 8859-16 (CB); VENTURA_INT (CB); |
|
| found in languages: af [Afrikaans]; cy [Welsh]; fr [French]; fy [Frisian]; lb [Luxembourgian]; nl [Dutch]; sq [Albanian]; sv [Swedish]; wo [Wolof]; yap [Yapese]; dink [Dinka]; sla [Kashubian]; |
|
| used in romanization of: be_r [Belarusian (cyrillic)]; ru_r [Russian (cyrillic)]; | |
| lowercase: 00EB |
0xCC
 UTF-8 (c4, 9a) � |
name: LATIN CAPITAL LETTER E WITH CARON |
| old name: |
|
| Adobe glyph name: Ecaron | |
| mnemonic name(s): <E<> | |
| HTML 4 mnemonic name: | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 0045 030C | |
| comment: | |
| found in charsets: 8859-2 (CC); CP1250 (CC); CP852 (B7); CENTEURO (9D); | |
| found in languages: cs [Czech]; sorb1 [Lower Sorbian]; sorb2 [Upper Sorbian]; yo [Yoruba]; | |
| used in romanization of: zh_r [Chinese (sino-japanese)]; | |
| lowercase: 011B |
0xCD
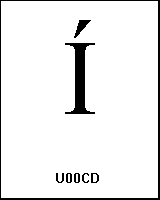 UTF-8 (c3, 8d) � |
name: LATIN CAPITAL LETTER I WITH ACUTE |
| old name: |
|
| Adobe glyph name: Iacute | |
| mnemonic name(s): <I'> | |
| HTML 4 mnemonic name:Í | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 0049 0301 | |
| comment: | |
| found in charsets: 8859-1 (CD); 8859-10 (CD); 8859-14 (CD); 8859-15 (CD); 8859-2 (CD); 8859-3 (CD); 8859-4 (CD); 8859-9 (CD); CP1250 (CD); CP1252 (CD); CP1254 (CD); CP1258 (CD); CP850 (D6); CP852 (D6); CP857 (D6); CP860 (8B); CP861 (A5); ROMAN (EA); CP1116 (D6); CP1122 (75); SAMI_WIN (CD); SAMI_MAC (EA); CENTEURO (EA); 8859-16 (CD); VENTURA_INT (CD); |
|
| found in languages: ku [Kurdish]; ca [Catalan]; cs [Czech]; cy [Welsh]; da [Danish]; es [Spanish]; fo [Faroese]; ga [Irish]; gl [Galician]; gn [Guaraní]; hu [Hungarian]; is [Icelandic]; it [Italian]; kl [Greenlandic]; nl [Dutch]; oc [Occitan]; pt [Portuguese]; sk [Slovak]; tl [Pilipino (Tagalog)]; vi [Vietnamese]; yo [Yoruba]; |
|
| used in romanization of: el_r [Greek (greek)]; tg_r [Tajik (cyrillic)]; zh_r [Chinese (sino-japanese)]; | |
| lowercase: 00ED |
0xCE
 UTF-8 (c3, 8e) � |
name: LATIN CAPITAL LETTER I WITH CIRCUMFLEX |
| old name: |
|
| Adobe glyph name: Icircumflex | |
| mnemonic name(s): <I/>> | |
| HTML 4 mnemonic name:Î | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 0049 0302 | |
| comment: | |
| found in charsets: 8859-1 (CE); 8859-10 (CE); 8859-14 (CE); 8859-15 (CE); 8859-2 (CE); 8859-3 (CE); 8859-4 (CE); 8859-9 (CE); CP1250 (CE); CP1252 (CE); CP1254 (CE); CP1258 (CE); CP850 (D7); CP852 (D7); CP857 (D7); CP863 (A8); ROMAN (EB); CP1116 (D7); CP1122 (76); SAMI_WIN (CE); SAMI_MAC (EB); 8859-16 (CE); VENTURA_INT (CE); |
|
| found in languages: af [Afrikaans]; ku [Kurdish]; cy [Welsh]; fr [French]; fy [Frisian]; it [Italian]; kl [Greenlandic]; lb [Luxembourgian]; mt [Maltese]; rm [(Rhaeto-)Romance]; ro [Romanian]; tl [Pilipino (Tagalog)]; tr [Turkish]; yo [Yoruba]; wa [Walloon]; |
|
| used in romanization of: ar_r [Arabic (perso-arabic)]; | |
| lowercase: 00EE |
0xCF
 UTF-8 (c4, 8e) � |
name: LATIN CAPITAL LETTER D WITH CARON |
| old name: |
|
| Adobe glyph name: Dcaron | |
| mnemonic name(s): <D<> | |
| HTML 4 mnemonic name: | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 0044 030C | |
| comment: | |
| found in charsets: 8859-2 (CF); CP1250 (CF); CP852 (D2); CENTEURO (91); | |
| found in languages: cs [Czech]; sk [Slovak]; | |
| used in romanization of: | |
| lowercase: 010F |
0xD0
 UTF-8 (c4, 90) � |
name: LATIN CAPITAL LETTER D WITH STROKE |
| old name: |
|
| Adobe glyph name: Dcroat | |
| mnemonic name(s): <D//> | |
| HTML 4 mnemonic name: | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| comment: | |
| Note: 00D0 ETH (Icelandic) is different to 0110 LATIN CAPITAL LETTER D WITH STROKE (used in Croatian/Slovenian and Sami) and different to 0189 LATIN CAPITAL LETTER AFRICAN D (African languages) |
|
| found in charsets: 8859-10 (A9); 8859-2 (D0); 8859-4 (D0); CP1250 (D0); CP1258 (D0); CP852 (D1); SAMI_WIN (89); SAMI_MAC (B0); 8859-16 (D0); | |
| found in languages: bs [Bosnian]; hr [Croatian]; sami1 [Inari Sámi]; sami2 [North Sámi]; sami4 [Skolt Sámi]; sl [Slovenian]; vi [Vietnamese]; sr [Serbian]; |
|
| used in romanization of: mk_r [Macedonian (cyrillic)]; sr_r [Serbian (cyrillic)]; | |
| lowercase: 0111 |
0xD1
 UTF-8 (c5, 83) � |
name: LATIN CAPITAL LETTER N WITH ACUTE |
| old name: |
|
| Adobe glyph name: Nacute | |
| mnemonic name(s): <N'> | |
| HTML 4 mnemonic name: | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 004E 0301 | |
| comment: | |
| found in charsets: 8859-13 (D1); 8859-2 (D1); CP1250 (D1); CP1257 (D1); CP775 (E3); CP852 (E3); CENTEURO (C1); 8859-16 (D1); | |
| found in languages: pl [Polish]; sorb1 [Lower Sorbian]; sorb2 [Upper Sorbian]; yo [Yoruba]; sla [Kashubian]; be [Belarusian]; | |
| used in romanization of: ne_r [Nepali (devanagari)]; | |
| lowercase: 0144 |
0xD2
 UTF-8 (c5, 87) � |
name: LATIN CAPITAL LETTER N WITH CARON |
| old name: |
|
| Adobe glyph name: Ncaron | |
| mnemonic name(s): <N<> | |
| HTML 4 mnemonic name: | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 004E 030C | |
| comment: | |
| found in charsets: 8859-2 (D2); CP1250 (D2); CP852 (D5); CENTEURO (C5); | |
| found in languages: cs [Czech]; sk [Slovak]; tk [Turkmen]; | |
| used in romanization of: | |
| lowercase: 0148 |
0xD3
 UTF-8 (c3, 93) � |
name: LATIN CAPITAL LETTER O WITH ACUTE |
| old name: |
|
| Adobe glyph name: Oacute | |
| mnemonic name(s): <O'> | |
| HTML 4 mnemonic name:Ó | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 004F 0301 | |
| comment: | |
| found in charsets: 8859-1 (D3); 8859-10 (D3); 8859-13 (D3); 8859-14 (D3); 8859-15 (D3); 8859-2 (D3); 8859-3 (D3); 8859-9 (D3); CP1250 (D3); CP1252 (D3); CP1254 (D3); CP1257 (D3); CP1258 (D3); CP775 (E0); CP850 (E0); CP852 (E0); CP857 (E0); CP860 (9F); CP861 (A6); ROMAN (EE); CP1116 (E0); CP1122 (EE); SAMI_WIN (D3); SAMI_MAC (EE); CENTEURO (EE); 8859-16 (D3); VENTURA_INT (D1); |
|
| found in languages: ca [Catalan]; cs [Czech]; cy [Welsh]; da [Danish]; es [Spanish]; fo [Faroese]; ga [Irish]; gd [Gaelic (Scots)]; gl [Galician]; gn [Guaraní]; hu [Hungarian]; is [Icelandic]; it [Italian]; nl [Dutch]; no [Norwegian]; oc [Occitan]; pl [Polish]; pt [Portuguese]; sk [Slovak]; sorb2 [Upper Sorbian]; tl [Pilipino (Tagalog)]; vi [Vietnamese]; wo [Wolof]; yo [Yoruba]; sla [Kashubian]; |
|
| used in romanization of: el_r [Greek (greek)]; km_r [Khmer (khmer)]; zh_r [Chinese (sino-japanese)]; | |
| lowercase: 00F3 |
0xD4
 UTF-8 (c3, 94) � |
name: LATIN CAPITAL LETTER O WITH CIRCUMFLEX |
| old name: |
|
| Adobe glyph name: Ocircumflex | |
| mnemonic name(s): <O/>> | |
| HTML 4 mnemonic name:Ô | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 004F 0302 | |
| comment: | |
| found in charsets: 8859-1 (D4); 8859-10 (D4); 8859-14 (D4); 8859-15 (D4); 8859-2 (D4); 8859-3 (D4); 8859-4 (D4); 8859-9 (D4); CP1250 (D4); CP1252 (D4); CP1254 (D4); CP1258 (D4); CP850 (E2); CP852 (E2); CP857 (E2); CP860 (8C); CP863 (99); ROMAN (EF); CP1116 (E2); CP1122 (EB); SAMI_WIN (D4); SAMI_MAC (EF); CENTEURO (EF); 8859-16 (D4); VENTURA_INT (D2); |
|
| found in languages: af [Afrikaans]; br [Breton]; cy [Welsh]; en [English]; fr [French]; fy [Frisian]; kl [Greenlandic]; lb [Luxembourgian]; mg [Malagasy]; nl [Dutch]; no [Norwegian]; pt [Portuguese]; sk [Slovak]; tn [Tswana]; vi [Vietnamese]; yo [Yoruba]; sla [Kashubian]; wa [Walloon]; nso [Northern Sotho]; |
|
| used in romanization of: ar_r [Arabic (perso-arabic)]; ja_r [Japanese (sino-japanese)]; km_r [Khmer (khmer)]; lo_r [Laotian (laotian)]; my_r [Burmese (burmese)]; |
|
| lowercase: 00F4 |
0xD5
 UTF-8 (c5, 90) � |
name: LATIN CAPITAL LETTER O WITH DOUBLE ACUTE |
| old name: |
|
| Adobe glyph name: Ohungarumlaut | |
| mnemonic name(s): <O"> | |
| HTML 4 mnemonic name: | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 004F 030B | |
| comment: | |
| found in charsets: 8859-2 (D5); CP1250 (D5); CP852 (8A); CENTEURO (CC); 8859-16 (D5); | |
| found in languages: hu [Hungarian]; | |
| used in romanization of: | |
| lowercase: 0151 |
0xD6
 UTF-8 (c3, 96) � |
name: LATIN CAPITAL LETTER O WITH DIAERESIS |
| old name: |
|
| Adobe glyph name: Odieresis | |
| mnemonic name(s): <O:> | |
| HTML 4 mnemonic name:Ö | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 004F 0308 | |
| comment: | |
| found in charsets: 8859-1 (D6); 8859-10 (D6); 8859-13 (D6); 8859-14 (D6); 8859-15 (D6); 8859-2 (D6); 8859-3 (D6); 8859-4 (D6); 8859-9 (D6); CP1250 (D6); CP1252 (D6); CP1254 (D6); CP1257 (D6); CP1258 (D6); CP437 (99); CP775 (99); CP850 (99); CP852 (99); CP857 (99); CP861 (99); CP865 (99); ROMAN (85); CP1116 (99); CP1122 (7C); SAMI_WIN (D6); SAMI_MAC (85); CENTEURO (85); 8859-16 (D6); VENTURA_INT (99); |
|
| found in languages: az [Azerbaijani]; cy [Welsh]; de [German]; et [Estonian]; fi [Finnish]; fy [Frisian]; hu [Hungarian]; is [Icelandic]; lb [Luxembourgian]; nl [Dutch]; sami5 [South Sámi]; sl [Slovenian]; sv [Swedish]; tk [Turkmen]; tr [Turkish]; yap [Yapese]; dink [Dinka]; |
|
| used in romanization of: kk_r [Kazakh (cyrillic)]; ky_r [Kyrgyz (cyrillic)]; mn_r [Mongolian (cyrillic)]; tk_r [Turkmen (cyrillic)]; | |
| lowercase: 00F6 |
0xD7
 UTF-8 (c3, 97) � |
name: MULTIPLICATION SIGN |
| old name: | |
| Adobe glyph name: multiply | |
| mnemonic name(s): <*X> | |
| HTML 4 mnemonic name:× | |
| category: Sm (Symbol, Math) | |
| combining: 0 | |
| comment: | |
| found in charsets: 8859-1 (D7); 8859-13 (D7); 8859-15 (D7); 8859-2 (D7); 8859-3 (D7); 8859-4 (D7); 8859-8 (AA); 8859-9 (D7); CP1250 (D7); CP1252 (D7); CP1254 (D7); CP1255 (AA); CP1256 (D7); CP1257 (D7); CP1258 (D7); CP775 (9E); CP850 (9E); CP852 (9E); CP857 (E8); CP864 (DE); CP1116 (9E); CP1122 (BF); SAMI_WIN (D7); VENTURA_SYM (94); |
|
| found in languages: | |
| used in romanization of: |
0xD8
 UTF-8 (c5, 98) � |
name: LATIN CAPITAL LETTER R WITH CARON |
| old name: |
|
| Adobe glyph name: Rcaron | |
| mnemonic name(s): <R<> | |
| HTML 4 mnemonic name: | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 0052 030C | |
| comment: | |
| found in charsets: 8859-2 (D8); CP1250 (D8); CP852 (FC); CENTEURO (DB); | |
| found in languages: cs [Czech]; sorb2 [Upper Sorbian]; | |
| used in romanization of: | |
| lowercase: 0159 |
0xD9
 UTF-8 (c5, ae) ĹŽ |
name: LATIN CAPITAL LETTER U WITH RING ABOVE |
| old name: |
|
| Adobe glyph name: Uring | |
| mnemonic name(s): <U0> | |
| HTML 4 mnemonic name: | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 0055 030A | |
| comment: | |
| found in charsets: 8859-2 (D9); CP1250 (D9); CP852 (DE); CENTEURO (F1); | |
| found in languages: cs [Czech]; | |
| used in romanization of: | |
| lowercase: 016F |
0xDA
 UTF-8 (c3, 9a) � |
name: LATIN CAPITAL LETTER U WITH ACUTE |
| old name: |
|
| Adobe glyph name: Uacute | |
| mnemonic name(s): <U'> | |
| HTML 4 mnemonic name:Ú | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 0055 0301 | |
| comment: | |
| found in charsets: 8859-1 (DA); 8859-10 (DA); 8859-14 (DA); 8859-15 (DA); 8859-2 (DA); 8859-3 (DA); 8859-4 (DA); 8859-9 (DA); CP1250 (DA); CP1252 (DA); CP1254 (DA); CP1258 (DA); CP850 (E9); CP852 (E9); CP857 (E9); CP860 (96); CP861 (A7); ROMAN (F2); CP1116 (E9); CP1122 (FE); SAMI_WIN (DA); SAMI_MAC (F2); CENTEURO (F2); 8859-16 (DA); VENTURA_INT (D6); |
|
| found in languages: ku [Kurdish]; ca [Catalan]; cs [Czech]; cy [Welsh]; da [Danish]; es [Spanish]; fo [Faroese]; fy [Frisian]; ga [Irish]; gl [Galician]; gn [Guaraní]; hu [Hungarian]; is [Icelandic]; it [Italian]; kl [Greenlandic]; nl [Dutch]; oc [Occitan]; pt [Portuguese]; sk [Slovak]; tl [Pilipino (Tagalog)]; vi [Vietnamese]; yo [Yoruba]; |
|
| used in romanization of: el_r [Greek (greek)]; zh_r [Chinese (sino-japanese)]; | |
| lowercase: 00FA |
0xDB
 UTF-8 (c5, b0) Ĺ° |
name: LATIN CAPITAL LETTER U WITH DOUBLE ACUTE |
| old name: |
|
| Adobe glyph name: Uhungarumlaut | |
| mnemonic name(s): <U"> | |
| HTML 4 mnemonic name: | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 0055 030B | |
| comment: | |
| found in charsets: 8859-2 (DB); CP1250 (DB); CP852 (EB); CENTEURO (F4); 8859-16 (D8); | |
| found in languages: hu [Hungarian]; | |
| used in romanization of: | |
| lowercase: 0171 |
0xDC
 UTF-8 (c3, 9c) � |
name: LATIN CAPITAL LETTER U WITH DIAERESIS |
| old name: |
|
| Adobe glyph name: Udieresis | |
| mnemonic name(s): <U:> | |
| HTML 4 mnemonic name:Ü | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 0055 0308 | |
| comment: | |
| found in charsets: 8859-1 (DC); 8859-10 (DC); 8859-13 (DC); 8859-14 (DC); 8859-15 (DC); 8859-2 (DC); 8859-3 (DC); 8859-4 (DC); 8859-9 (DC); CP1250 (DC); CP1252 (DC); CP1254 (DC); CP1257 (DC); CP1258 (DC); CP437 (9A); CP775 (9A); CP850 (9A); CP852 (9A); CP857 (9A); CP860 (9A); CP861 (9A); CP863 (9A); CP865 (9A); ROMAN (86); CP1116 (9A); CP1122 (FC); SAMI_WIN (DC); SAMI_MAC (86); CENTEURO (86); 8859-16 (DC); VENTURA_INT (9A); |
|
| found in languages: az [Azerbaijani]; bi [Bislama]; br [Breton]; ca [Catalan]; ch [Chamorro]; cy [Welsh]; de [German]; es [Spanish]; et [Estonian]; eu [Basque]; fr [French]; fy [Frisian]; gl [Galician]; hu [Hungarian]; lb [Luxembourgian]; nl [Dutch]; pt [Portuguese]; sl [Slovenian]; sv [Swedish]; tk [Turkmen]; tr [Turkish]; tt [Tatar]; cor [Cornish]; |
|
| used in romanization of: kk_r [Kazakh (cyrillic)]; ky_r [Kyrgyz (cyrillic)]; mn_r [Mongolian (cyrillic)]; tk_r [Turkmen (cyrillic)]; zh_r [Chinese (sino-japanese)]; |
|
| lowercase: 00FC |
0xDD
 UTF-8 (c3, 9d) � |
name: LATIN CAPITAL LETTER Y WITH ACUTE |
| old name: |
|
| Adobe glyph name: Yacute | |
| mnemonic name(s): <Y'> | |
| HTML 4 mnemonic name:Ý | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 0059 0301 | |
| comment: | |
| found in charsets: 8859-1 (DD); 8859-10 (DD); 8859-14 (DD); 8859-15 (DD); 8859-2 (DD); CP1250 (DD); CP1252 (DD); CP850 (ED); CP852 (ED); CP861 (97); CP1116 (ED); CP1122 (AD); SAMI_WIN (DD); SAMI_MAC (A0); CENTEURO (F8); |
|
| found in languages: cs [Czech]; cy [Welsh]; da [Danish]; fo [Faroese]; is [Icelandic]; sk [Slovak]; tk [Turkmen]; vi [Vietnamese]; | |
| used in romanization of: el_r [Greek (greek)]; | |
| lowercase: 00FD |
0xDE
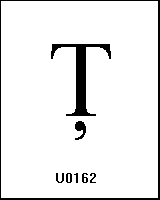 UTF-8 (c5, a2) Ţ |
name: LATIN CAPITAL LETTER T WITH CEDILLA |
| old name: |
|
| Adobe glyph name: Tcommaaccent | |
| mnemonic name(s): <T,> | |
| HTML 4 mnemonic name: | |
| category: Lu (Letter, Uppercase) | |
| combining: 0 | |
| decomposition info: 0054 0327 | |
| comment: * | |
| Note: Please see note 1 |
|
| found in charsets: 8859-2 (DE); CP1250 (DE); CP852 (DD); | |
| found in languages: livo [Livonian]; | |
| used in romanization of: ar_r [Arabic (perso-arabic)]; | |
| lowercase: 0163 |
0xDF
 UTF-8 (c3, 9f) � |
name: LATIN SMALL LETTER SHARP S |
| old name: | |
| Adobe glyph name: germandbls | |
| mnemonic name(s): <ss> | |
| HTML 4 mnemonic name:ß | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| comment: German | |
| Note: ß is unique to the German language in Germany and Austria, Swiss German uses ss. The recent spelling reform in Germany also mandated ss in several contexts -- ß is retained at the end of the stem after a long vowel or diphthong. ß is not treated as a ligature (s+z). Also called eszet or sharp s. |
|
| found in charsets: 8859-1 (DF); 8859-10 (DF); 8859-13 (DF); 8859-14 (DF); 8859-15 (DF); 8859-2 (DF); 8859-3 (DF); 8859-4 (DF); 8859-9 (DF); CP1250 (DF); CP1252 (DF); CP1254 (DF); CP1257 (DF); CP1258 (DF); CP437 (E1); CP775 (E1); CP850 (E1); CP852 (E1); CP857 (E1); CP860 (E1); CP861 (E1); CP862 (E1); CP863 (E1); CP865 (E1); ROMAN (A7); CP1116 (E1); CP1122 (59); SAMI_WIN (DF); SAMI_MAC (A7); CENTEURO (A7); 8859-16 (DF); VENTURA_INT (D9); |
|
| found in languages: de [German]; lb [Luxembourgian]; | |
| used in romanization of: |
0xE0
 UTF-8 (c5, 95) � |
name: LATIN SMALL LETTER R WITH ACUTE |
| old name: |
|
| Adobe glyph name: racute | |
| mnemonic name(s): <r'> | |
| HTML 4 mnemonic name: | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 0072 0301 | |
| comment: | |
| found in charsets: 8859-2 (E0); CP1250 (E0); CP852 (EA); CENTEURO (DA); | |
| found in languages: sk [Slovak]; sorb1 [Lower Sorbian]; | |
| used in romanization of: | |
| uppercase: 0154 |
0xE1
 UTF-8 (c3, a1) ĂĄ |
name: LATIN SMALL LETTER A WITH ACUTE |
| old name: |
|
| Adobe glyph name: aacute | |
| mnemonic name(s): <a'> | |
| HTML 4 mnemonic name:á | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 0061 0301 | |
| comment: | |
| found in charsets: 8859-1 (E1); 8859-10 (E1); 8859-14 (E1); 8859-15 (E1); 8859-2 (E1); 8859-3 (E1); 8859-4 (E1); 8859-9 (E1); CP1250 (E1); CP1252 (E1); CP1254 (E1); CP1258 (E1); CP437 (A0); CP850 (A0); CP852 (A0); CP857 (A0); CP860 (A0); CP861 (A0); CP862 (A0); CP865 (A0); ROMAN (87); CP1116 (A0); CP1122 (45); SAMI_WIN (E1); SAMI_MAC (87); CENTEURO (87); 8859-16 (E1); VENTURA_INT (A0); |
|
| found in languages: cs [Czech]; cy [Welsh]; da [Danish]; es [Spanish]; fo [Faroese]; ga [Irish]; gd [Gaelic (Scots)]; gl [Galician]; gn [Guaraní]; hu [Hungarian]; is [Icelandic]; it [Italian]; kl [Greenlandic]; mg [Malagasy]; nl [Dutch]; oc [Occitan]; pt [Portuguese]; sami1 [Inari Sámi]; sami2 [North Sámi]; sami3 [Lule Sámi]; sk [Slovak]; sv [Swedish]; tl [Pilipino (Tagalog)]; vi [Vietnamese]; yo [Yoruba]; |
|
| used in romanization of: ar_r [Arabic (perso-arabic)]; el_r [Greek (greek)]; fa_r [Persian (perso-arabic)]; km_r [Khmer (khmer)]; zh_r [Chinese (sino-japanese)]; |
|
| uppercase: 00C1 |
0xE2
 UTF-8 (c3, a2) â |
name: LATIN SMALL LETTER A WITH CIRCUMFLEX |
| old name: |
|
| Adobe glyph name: acircumflex | |
| mnemonic name(s): <a/>> | |
| HTML 4 mnemonic name:â | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 0061 0302 | |
| comment: | |
| found in charsets: 8859-1 (E2); 8859-10 (E2); 8859-14 (E2); 8859-15 (E2); 8859-2 (E2); 8859-3 (E2); 8859-4 (E2); 8859-9 (E2); CP1250 (E2); CP1252 (E2); CP1254 (E2); CP1256 (E2); CP1258 (E2); CP437 (83); CP850 (83); CP852 (83); CP857 (83); CP860 (83); CP861 (83); CP863 (83); CP865 (83); ROMAN (89); CP1116 (83); CP1122 (42); SAMI_WIN (E2); SAMI_MAC (89); 8859-16 (E2); VENTURA_INT (83); |
|
| found in languages: br [Breton]; ch [Chamorro]; cy [Welsh]; fr [French]; fy [Frisian]; kl [Greenlandic]; lb [Luxembourgian]; nl [Dutch]; pt [Portuguese]; ro [Romanian]; sami1 [Inari Sámi]; sami4 [Skolt Sámi]; tl [Pilipino (Tagalog)]; tr [Turkish]; vi [Vietnamese]; yo [Yoruba]; wa [Walloon]; |
|
| used in romanization of: ar_r [Arabic (perso-arabic)]; km_r [Khmer (khmer)]; | |
| uppercase: 00C2 |
0xE3
 UTF-8 (c4, 83) � |
name: LATIN SMALL LETTER A WITH BREVE |
| old name: |
|
| Adobe glyph name: abreve | |
| mnemonic name(s): <a(> | |
| HTML 4 mnemonic name: | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 0061 0306 | |
| comment: | |
| found in charsets: 8859-2 (E3); CP1250 (E3); CP1258 (E3); CP852 (C7); 8859-16 (E3); | |
| found in languages: ro [Romanian]; vi [Vietnamese]; | |
| used in romanization of: km_r [Khmer (khmer)]; | |
| uppercase: 0102 |
0xE4
 UTF-8 (c3, a4) ä |
name: LATIN SMALL LETTER A WITH DIAERESIS |
| old name: |
|
| Adobe glyph name: adieresis | |
| mnemonic name(s): <a:> | |
| HTML 4 mnemonic name:ä | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 0061 0308 | |
| comment: | |
| found in charsets: 8859-1 (E4); 8859-10 (E4); 8859-13 (E4); 8859-14 (E4); 8859-15 (E4); 8859-2 (E4); 8859-3 (E4); 8859-4 (E4); 8859-9 (E4); CP1250 (E4); CP1252 (E4); CP1254 (E4); CP1257 (E4); CP1258 (E4); CP437 (84); CP775 (84); CP850 (84); CP852 (84); CP857 (84); CP861 (84); CP865 (84); ROMAN (8A); CP1116 (84); CP1122 (C0); SAMI_WIN (E4); SAMI_MAC (8A); CENTEURO (8A); 8859-16 (E4); VENTURA_INT (84); |
|
| found in languages: az [Azerbaijani]; cy [Welsh]; de [German]; et [Estonian]; fi [Finnish]; fy [Frisian]; lb [Luxembourgian]; livo [Livonian]; nl [Dutch]; sami1 [Inari Sámi]; sami3 [Lule Sámi]; sami4 [Skolt Sámi]; sami5 [South Sámi]; sk [Slovak]; sl [Slovenian]; sv [Swedish]; tk [Turkmen]; yap [Yapese]; dink [Dinka]; |
|
| used in romanization of: kk_r [Kazakh (cyrillic)]; tk_r [Turkmen (cyrillic)]; | |
| uppercase: 00C4 |
0xE5
 UTF-8 (c4, ba) Äş |
name: LATIN SMALL LETTER L WITH ACUTE |
| old name: |
|
| Adobe glyph name: lacute | |
| mnemonic name(s): <l'> | |
| HTML 4 mnemonic name: | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 006C 0301 | |
| comment: | |
| found in charsets: 8859-2 (E5); CP1250 (E5); CP852 (92); CENTEURO (BE); | |
| found in languages: sk [Slovak]; | |
| used in romanization of: | |
| uppercase: 0139 |
0xE6
 UTF-8 (c4, 87) � |
name: LATIN SMALL LETTER C WITH ACUTE |
| old name: |
|
| Adobe glyph name: cacute | |
| mnemonic name(s): <c'> | |
| HTML 4 mnemonic name: | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 0063 0301 | |
| comment: | |
| found in charsets: 8859-13 (E3); 8859-2 (E6); CP1250 (E6); CP1257 (E3); CP775 (87); CP852 (86); CENTEURO (8D); 8859-16 (E5); | |
| found in languages: bs [Bosnian]; hr [Croatian]; pl [Polish]; sl [Slovenian]; sorb1 [Lower Sorbian]; sorb2 [Upper Sorbian]; sla [Kashubian]; be [Belarusian]; sr [Serbian]; |
|
| used in romanization of: mk_r [Macedonian (cyrillic)]; sr_r [Serbian (cyrillic)]; | |
| uppercase: 0106 |
0xE7
 UTF-8 (c3, a7) ç |
name: LATIN SMALL LETTER C WITH CEDILLA |
| old name: |
|
| Adobe glyph name: ccedilla | |
| mnemonic name(s): <c,> | |
| HTML 4 mnemonic name:ç | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 0063 0327 | |
| comment: | |
| found in charsets: 8859-1 (E7); 8859-14 (E7); 8859-15 (E7); 8859-2 (E7); 8859-3 (E7); 8859-9 (E7); CP1250 (E7); CP1252 (E7); CP1254 (E7); CP1256 (E7); CP1258 (E7); CP437 (87); CP850 (87); CP852 (87); CP857 (87); CP860 (87); CP861 (87); CP863 (87); CP865 (87); ROMAN (8D); CP1116 (87); CP1122 (48); SAMI_WIN (E7); SAMI_MAC (8D); 8859-16 (E7); VENTURA_INT (87); |
|
| found in languages: az [Azerbaijani]; ku [Kurdish]; ca [Catalan]; en [English]; es [Spanish]; eu [Basque]; fr [French]; oc [Occitan]; pt [Portuguese]; sq [Albanian]; tk [Turkmen]; tr [Turkish]; tt [Tatar]; wa [Walloon]; |
|
| used in romanization of: ar_r [Arabic (perso-arabic)]; | |
| uppercase: 00C7 |
0xE8
 UTF-8 (c4, 8d) � |
name: LATIN SMALL LETTER C WITH CARON |
| old name: |
|
| Adobe glyph name: ccaron | |
| mnemonic name(s): <c<> | |
| HTML 4 mnemonic name: | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 0063 030C | |
| comment: | |
| found in charsets: 8859-10 (E8); 8859-13 (E8); 8859-2 (E8); 8859-4 (E8); CP1250 (E8); CP1257 (E8); CP775 (D1); CP852 (9F); SAMI_WIN (84); SAMI_MAC (B8); CENTEURO (8B); 8859-16 (B9); |
|
| found in languages: bs [Bosnian]; cs [Czech]; hr [Croatian]; lt [Lithuanian]; lv [Latvian]; sami1 [Inari Sámi]; sami2 [North Sámi]; sami4 [Skolt Sámi]; sk [Slovak]; sl [Slovenian]; sorb1 [Lower Sorbian]; sorb2 [Upper Sorbian]; be [Belarusian]; sr [Serbian]; |
|
| used in romanization of: be_r [Belarusian (cyrillic)]; bg_r [Bulgarian (cyrillic)]; mk_r [Macedonian (cyrillic)]; ru_r [Russian (cyrillic)]; sr_r [Serbian (cyrillic)]; |
|
| uppercase: 010C |
0xE9
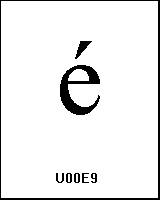 UTF-8 (c3, a9) ĂŠ |
name: LATIN SMALL LETTER E WITH ACUTE |
| old name: |
|
| Adobe glyph name: eacute | |
| mnemonic name(s): <e'> | |
| HTML 4 mnemonic name:é | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 0065 0301 | |
| comment: | |
| found in charsets: 8859-1 (E9); 8859-10 (E9); 8859-13 (E9); 8859-14 (E9); 8859-15 (E9); 8859-2 (E9); 8859-3 (E9); 8859-4 (E9); 8859-9 (E9); CP1250 (E9); CP1252 (E9); CP1254 (E9); CP1256 (E9); CP1257 (E9); CP1258 (E9); CP437 (82); CP775 (82); CP850 (82); CP852 (82); CP857 (82); CP860 (82); CP861 (82); CP863 (82); CP865 (82); ROMAN (8E); CP1116 (82); CP1122 (79); SAMI_WIN (E9); SAMI_MAC (8E); CENTEURO (8E); 8859-16 (E9); VENTURA_INT (82); |
|
| found in languages: af [Afrikaans]; ku [Kurdish]; bi [Bislama]; ca [Catalan]; cs [Czech]; cy [Welsh]; da [Danish]; de [German]; es [Spanish]; fr [French]; fy [Frisian]; ga [Irish]; gd [Gaelic (Scots)]; gl [Galician]; gn [Guaraní]; hu [Hungarian]; id [Indonesian]; is [Icelandic]; it [Italian]; kl [Greenlandic]; lb [Luxembourgian]; nl [Dutch]; no [Norwegian]; oc [Occitan]; pt [Portuguese]; rm [(Rhaeto-)Romance]; sk [Slovak]; sv [Swedish]; tl [Pilipino (Tagalog)]; vi [Vietnamese]; wo [Wolof]; yo [Yoruba]; sla [Kashubian]; wa [Walloon]; |
|
| used in romanization of: ar_r [Arabic (perso-arabic)]; el_r [Greek (greek)]; he_r [Hebrew (hebrew)]; km_r [Khmer (khmer)]; lo_r [Laotian (laotian)]; zh_r [Chinese (sino-japanese)]; |
|
| uppercase: 00C9 |
0xEA
 UTF-8 (c4, 99) � |
name: LATIN SMALL LETTER E WITH OGONEK |
| old name: |
|
| Adobe glyph name: eogonek | |
| mnemonic name(s): <e;> | |
| HTML 4 mnemonic name: | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 0065 0328 | |
| comment: | |
| found in charsets: 8859-10 (EA); 8859-13 (E6); 8859-2 (EA); 8859-4 (EA); CP1250 (EA); CP1257 (E6); CP775 (D2); CP852 (A9); CENTEURO (AB); 8859-16 (FD); |
|
| found in languages: lt [Lithuanian]; pl [Polish]; sla [Kashubian]; | |
| used in romanization of: | |
| uppercase: 0118 |
0xEB
 UTF-8 (c3, ab) ĂŤ |
name: LATIN SMALL LETTER E WITH DIAERESIS |
| old name: |
|
| Adobe glyph name: edieresis | |
| mnemonic name(s): <e:> | |
| HTML 4 mnemonic name:ë | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 0065 0308 | |
| comment: | |
| found in charsets: 8859-1 (EB); 8859-10 (EB); 8859-14 (EB); 8859-15 (EB); 8859-2 (EB); 8859-3 (EB); 8859-4 (EB); 8859-9 (EB); CP1250 (EB); CP1252 (EB); CP1254 (EB); CP1256 (EB); CP1258 (EB); CP437 (89); CP850 (89); CP852 (89); CP857 (89); CP861 (89); CP863 (89); CP865 (89); ROMAN (91); CP1116 (89); CP1122 (53); SAMI_WIN (EB); SAMI_MAC (91); 8859-16 (EB); VENTURA_INT (89); |
|
| found in languages: af [Afrikaans]; cy [Welsh]; fr [French]; fy [Frisian]; lb [Luxembourgian]; nl [Dutch]; sq [Albanian]; sv [Swedish]; wo [Wolof]; yap [Yapese]; dink [Dinka]; sla [Kashubian]; |
|
| used in romanization of: be_r [Belarusian (cyrillic)]; ru_r [Russian (cyrillic)]; | |
| uppercase: 00CB |
0xEC
 UTF-8 (c4, 9b) � |
name: LATIN SMALL LETTER E WITH CARON |
| old name: |
|
| Adobe glyph name: ecaron | |
| mnemonic name(s): <e<> | |
| HTML 4 mnemonic name: | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 0065 030C | |
| comment: | |
| found in charsets: 8859-2 (EC); CP1250 (EC); CP852 (D8); CENTEURO (9E); | |
| found in languages: cs [Czech]; sorb1 [Lower Sorbian]; sorb2 [Upper Sorbian]; yo [Yoruba]; | |
| used in romanization of: zh_r [Chinese (sino-japanese)]; | |
| uppercase: 011A |
0xED
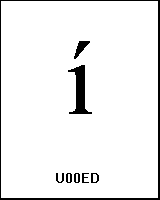 UTF-8 (c3, ad) Ă |
name: LATIN SMALL LETTER I WITH ACUTE |
| old name: |
|
| Adobe glyph name: iacute | |
| mnemonic name(s): <i'> | |
| HTML 4 mnemonic name:í | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 0069 0301 | |
| comment: | |
| found in charsets: 8859-1 (ED); 8859-10 (ED); 8859-14 (ED); 8859-15 (ED); 8859-2 (ED); 8859-3 (ED); 8859-4 (ED); 8859-9 (ED); CP1250 (ED); CP1252 (ED); CP1254 (ED); CP1258 (ED); CP437 (A1); CP850 (A1); CP852 (A1); CP857 (A1); CP860 (A1); CP861 (A1); CP862 (A1); CP865 (A1); ROMAN (92); CP1116 (A1); CP1122 (55); SAMI_WIN (ED); SAMI_MAC (92); CENTEURO (92); 8859-16 (ED); VENTURA_INT (A1); |
|
| found in languages: ku [Kurdish]; ca [Catalan]; cs [Czech]; cy [Welsh]; da [Danish]; es [Spanish]; fo [Faroese]; ga [Irish]; gl [Galician]; gn [Guaraní]; hu [Hungarian]; is [Icelandic]; it [Italian]; kl [Greenlandic]; nl [Dutch]; oc [Occitan]; pt [Portuguese]; sk [Slovak]; tl [Pilipino (Tagalog)]; vi [Vietnamese]; yo [Yoruba]; |
|
| used in romanization of: el_r [Greek (greek)]; tg_r [Tajik (cyrillic)]; zh_r [Chinese (sino-japanese)]; | |
| uppercase: 00CD |
0xEE
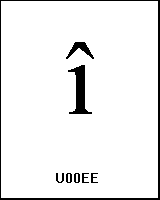 UTF-8 (c3, ae) ĂŽ |
name: LATIN SMALL LETTER I WITH CIRCUMFLEX |
| old name: |
|
| Adobe glyph name: icircumflex | |
| mnemonic name(s): <i/>> | |
| HTML 4 mnemonic name:î | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 0069 0302 | |
| comment: | |
| found in charsets: 8859-1 (EE); 8859-10 (EE); 8859-14 (EE); 8859-15 (EE); 8859-2 (EE); 8859-3 (EE); 8859-4 (EE); 8859-9 (EE); CP1250 (EE); CP1252 (EE); CP1254 (EE); CP1256 (EE); CP1258 (EE); CP437 (8C); CP850 (8C); CP852 (8C); CP857 (8C); CP863 (8C); CP865 (8C); ROMAN (94); CP1116 (8C); CP1122 (56); SAMI_WIN (EE); SAMI_MAC (94); 8859-16 (EE); VENTURA_INT (8C); |
|
| found in languages: af [Afrikaans]; ku [Kurdish]; cy [Welsh]; fr [French]; fy [Frisian]; it [Italian]; kl [Greenlandic]; lb [Luxembourgian]; mt [Maltese]; rm [(Rhaeto-)Romance]; ro [Romanian]; tl [Pilipino (Tagalog)]; tr [Turkish]; yo [Yoruba]; wa [Walloon]; |
|
| used in romanization of: ar_r [Arabic (perso-arabic)]; | |
| uppercase: 00CE |
0xEF
 UTF-8 (c4, 8f) � |
name: LATIN SMALL LETTER D WITH CARON |
| old name: |
|
| Adobe glyph name: dcaron | |
| mnemonic name(s): <d<> | |
| HTML 4 mnemonic name: | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 0064 030C | |
| comment: | |
| found in charsets: 8859-2 (EF); CP1250 (EF); CP852 (D4); CENTEURO (93); | |
| found in languages: cs [Czech]; sk [Slovak]; | |
| used in romanization of: | |
| uppercase: 010E |
0xF0
 UTF-8 (c4, 91) � |
name: LATIN SMALL LETTER D WITH STROKE |
| old name: |
|
| Adobe glyph name: dcroat | |
| mnemonic name(s): <d//> | |
| HTML 4 mnemonic name: | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| comment: | |
| found in charsets: 8859-10 (B9); 8859-2 (F0); 8859-4 (F0); CP1250 (F0); CP1258 (F0); CP852 (D0); SAMI_WIN (98); SAMI_MAC (B9); 8859-16 (F0); | |
| found in languages: bs [Bosnian]; hr [Croatian]; sami1 [Inari Sámi]; sami2 [North Sámi]; sami4 [Skolt Sámi]; sl [Slovenian]; vi [Vietnamese]; sr [Serbian]; |
|
| used in romanization of: mk_r [Macedonian (cyrillic)]; sr_r [Serbian (cyrillic)]; | |
| uppercase: 0110 |
0xF1
 UTF-8 (c5, 84) � |
name: LATIN SMALL LETTER N WITH ACUTE |
| old name: |
|
| Adobe glyph name: nacute | |
| mnemonic name(s): <n'> | |
| HTML 4 mnemonic name: | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 006E 0301 | |
| comment: | |
| found in charsets: 8859-13 (F1); 8859-2 (F1); CP1250 (F1); CP1257 (F1); CP775 (E7); CP852 (E4); CENTEURO (C4); 8859-16 (F1); | |
| found in languages: pl [Polish]; sorb1 [Lower Sorbian]; sorb2 [Upper Sorbian]; yo [Yoruba]; sla [Kashubian]; be [Belarusian]; | |
| used in romanization of: ne_r [Nepali (devanagari)]; | |
| uppercase: 0143 |
0xF2
 UTF-8 (c5, 88) � |
name: LATIN SMALL LETTER N WITH CARON |
| old name: |
|
| Adobe glyph name: ncaron | |
| mnemonic name(s): <n<> | |
| HTML 4 mnemonic name: | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 006E 030C | |
| comment: | |
| found in charsets: 8859-2 (F2); CP1250 (F2); CP852 (E5); CENTEURO (CB); | |
| found in languages: cs [Czech]; sk [Slovak]; tk [Turkmen]; | |
| used in romanization of: | |
| uppercase: 0147 |
0xF3
 UTF-8 (c3, b3) Ăł |
name: LATIN SMALL LETTER O WITH ACUTE |
| old name: |
|
| Adobe glyph name: oacute | |
| mnemonic name(s): <o'> | |
| HTML 4 mnemonic name:ó | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 006F 0301 | |
| comment: | |
| found in charsets: 8859-1 (F3); 8859-10 (F3); 8859-13 (F3); 8859-14 (F3); 8859-15 (F3); 8859-2 (F3); 8859-3 (F3); 8859-9 (F3); CP1250 (F3); CP1252 (F3); CP1254 (F3); CP1257 (F3); CP1258 (F3); CP437 (A2); CP775 (A2); CP850 (A2); CP852 (A2); CP857 (A2); CP860 (A2); CP861 (A2); CP862 (A2); CP863 (A2); CP865 (A2); ROMAN (97); CP1116 (A2); CP1122 (CE); SAMI_WIN (F3); SAMI_MAC (97); CENTEURO (97); 8859-16 (F3); VENTURA_INT (A2); |
|
| found in languages: ca [Catalan]; cs [Czech]; cy [Welsh]; da [Danish]; es [Spanish]; fo [Faroese]; ga [Irish]; gd [Gaelic (Scots)]; gl [Galician]; gn [Guaraní]; hu [Hungarian]; is [Icelandic]; it [Italian]; nl [Dutch]; no [Norwegian]; oc [Occitan]; pl [Polish]; pt [Portuguese]; sk [Slovak]; sorb2 [Upper Sorbian]; tl [Pilipino (Tagalog)]; vi [Vietnamese]; wo [Wolof]; yo [Yoruba]; sla [Kashubian]; |
|
| used in romanization of: el_r [Greek (greek)]; km_r [Khmer (khmer)]; zh_r [Chinese (sino-japanese)]; | |
| uppercase: 00D3 |
0xF4
 UTF-8 (c3, b4) Ă´ |
name: LATIN SMALL LETTER O WITH CIRCUMFLEX |
| old name: |
|
| Adobe glyph name: ocircumflex | |
| mnemonic name(s): <o/>> | |
| HTML 4 mnemonic name:ô | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 006F 0302 | |
| comment: | |
| found in charsets: 8859-1 (F4); 8859-10 (F4); 8859-14 (F4); 8859-15 (F4); 8859-2 (F4); 8859-3 (F4); 8859-4 (F4); 8859-9 (F4); CP1250 (F4); CP1252 (F4); CP1254 (F4); CP1256 (F4); CP1258 (F4); CP437 (93); CP850 (93); CP852 (93); CP857 (93); CP860 (93); CP861 (93); CP863 (93); CP865 (93); ROMAN (99); CP1116 (93); CP1122 (CB); SAMI_WIN (F4); SAMI_MAC (99); CENTEURO (99); 8859-16 (F4); VENTURA_INT (93); |
|
| found in languages: af [Afrikaans]; br [Breton]; cy [Welsh]; en [English]; fr [French]; fy [Frisian]; kl [Greenlandic]; lb [Luxembourgian]; mg [Malagasy]; nl [Dutch]; no [Norwegian]; pt [Portuguese]; sk [Slovak]; tn [Tswana]; vi [Vietnamese]; yo [Yoruba]; sla [Kashubian]; wa [Walloon]; nso [Northern Sotho]; |
|
| used in romanization of: ar_r [Arabic (perso-arabic)]; ja_r [Japanese (sino-japanese)]; km_r [Khmer (khmer)]; lo_r [Laotian (laotian)]; my_r [Burmese (burmese)]; |
|
| uppercase: 00D4 |
0xF5
 UTF-8 (c5, 91) � |
name: LATIN SMALL LETTER O WITH DOUBLE ACUTE |
| old name: |
|
| Adobe glyph name: ohungarumlaut | |
| mnemonic name(s): <o"> | |
| HTML 4 mnemonic name: | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 006F 030B | |
| comment: | |
| found in charsets: 8859-2 (F5); CP1250 (F5); CP852 (8B); CENTEURO (CE); 8859-16 (F5); | |
| found in languages: hu [Hungarian]; | |
| used in romanization of: | |
| uppercase: 0150 |
0xF6
 UTF-8 (c3, b6) Ăś |
name: LATIN SMALL LETTER O WITH DIAERESIS |
| old name: |
|
| Adobe glyph name: odieresis | |
| mnemonic name(s): <o:> | |
| HTML 4 mnemonic name:ö | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 006F 0308 | |
| comment: | |
| found in charsets: 8859-1 (F6); 8859-10 (F6); 8859-13 (F6); 8859-14 (F6); 8859-15 (F6); 8859-2 (F6); 8859-3 (F6); 8859-4 (F6); 8859-9 (F6); CP1250 (F6); CP1252 (F6); CP1254 (F6); CP1257 (F6); CP1258 (F6); CP437 (94); CP775 (94); CP850 (94); CP852 (94); CP857 (94); CP861 (94); CP865 (94); ROMAN (9A); CP1116 (94); CP1122 (6A); SAMI_WIN (F6); SAMI_MAC (9A); CENTEURO (9A); 8859-16 (F6); VENTURA_INT (94); |
|
| found in languages: az [Azerbaijani]; cy [Welsh]; de [German]; et [Estonian]; fi [Finnish]; fy [Frisian]; hu [Hungarian]; is [Icelandic]; lb [Luxembourgian]; nl [Dutch]; sami5 [South Sámi]; sl [Slovenian]; sv [Swedish]; tk [Turkmen]; tr [Turkish]; yap [Yapese]; dink [Dinka]; |
|
| used in romanization of: kk_r [Kazakh (cyrillic)]; ky_r [Kyrgyz (cyrillic)]; mn_r [Mongolian (cyrillic)]; tk_r [Turkmen (cyrillic)]; | |
| uppercase: 00D6 |
0xF7
 UTF-8 (c3, b7) á |
name: DIVISION SIGN |
| old name: | |
| Adobe glyph name: divide | |
| mnemonic name(s): <-:> | |
| HTML 4 mnemonic name:÷ | |
| category: Sm (Symbol, Math) | |
| combining: 0 | |
| comment: | |
| found in charsets: 8859-1 (F7); 8859-13 (F7); 8859-15 (F7); 8859-2 (F7); 8859-3 (F7); 8859-4 (F7); 8859-8 (BA); 8859-9 (F7); CP1250 (F7); CP1252 (F7); CP1254 (F7); CP1255 (BA); CP1256 (F7); CP1257 (F7); CP1258 (F7); CP437 (F6); CP737 (F6); CP775 (F6); CP850 (F6); CP852 (F6); CP857 (F6); CP860 (F6); CP861 (F6); CP862 (F6); CP863 (F6); CP864 (DD); CP865 (F6); ROMAN (D6); CP1116 (F6); CP1122 (E1); CP878 (9F); SAMI_WIN (F7); SAMI_MAC (D6); CENTEURO (D6); VENTURA_SYM (98); |
|
| found in languages: | |
| used in romanization of: |
0xF8
 UTF-8 (c5, 99) � |
name: LATIN SMALL LETTER R WITH CARON |
| old name: |
|
| Adobe glyph name: rcaron | |
| mnemonic name(s): <r<> | |
| HTML 4 mnemonic name: | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 0072 030C | |
| comment: | |
| found in charsets: 8859-2 (F8); CP1250 (F8); CP852 (FD); CENTEURO (DE); | |
| found in languages: cs [Czech]; sorb2 [Upper Sorbian]; | |
| used in romanization of: | |
| uppercase: 0158 |
0xF9
 UTF-8 (c5, af) ĹŻ |
name: LATIN SMALL LETTER U WITH RING ABOVE |
| old name: |
|
| Adobe glyph name: uring | |
| mnemonic name(s): <u0> | |
| HTML 4 mnemonic name: | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 0075 030A | |
| comment: | |
| found in charsets: 8859-2 (F9); CP1250 (F9); CP852 (85); CENTEURO (F3); | |
| found in languages: cs [Czech]; | |
| used in romanization of: | |
| uppercase: 016E |
0xFA
 UTF-8 (c3, ba) Ăş |
name: LATIN SMALL LETTER U WITH ACUTE |
| old name: |
|
| Adobe glyph name: uacute | |
| mnemonic name(s): <u'> | |
| HTML 4 mnemonic name:ú | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 0075 0301 | |
| comment: | |
| found in charsets: 8859-1 (FA); 8859-10 (FA); 8859-14 (FA); 8859-15 (FA); 8859-2 (FA); 8859-3 (FA); 8859-4 (FA); 8859-9 (FA); CP1250 (FA); CP1252 (FA); CP1254 (FA); CP1258 (FA); CP437 (A3); CP850 (A3); CP852 (A3); CP857 (A3); CP860 (A3); CP861 (A3); CP862 (A3); CP863 (A3); CP865 (A3); ROMAN (9C); CP1116 (A3); CP1122 (DE); SAMI_WIN (FA); SAMI_MAC (9C); CENTEURO (9C); 8859-16 (FA); VENTURA_INT (A3); |
|
| found in languages: ku [Kurdish]; ca [Catalan]; cs [Czech]; cy [Welsh]; da [Danish]; es [Spanish]; fo [Faroese]; fy [Frisian]; ga [Irish]; gl [Galician]; gn [Guaraní]; hu [Hungarian]; is [Icelandic]; it [Italian]; kl [Greenlandic]; nl [Dutch]; oc [Occitan]; pt [Portuguese]; sk [Slovak]; tl [Pilipino (Tagalog)]; vi [Vietnamese]; yo [Yoruba]; |
|
| used in romanization of: el_r [Greek (greek)]; zh_r [Chinese (sino-japanese)]; | |
| uppercase: 00DA |
0xFB
 UTF-8 (c5, b1) Ĺą |
name: LATIN SMALL LETTER U WITH DOUBLE ACUTE |
| old name: |
|
| Adobe glyph name: uhungarumlaut | |
| mnemonic name(s): <u"> | |
| HTML 4 mnemonic name: | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 0075 030B | |
| comment: | |
| found in charsets: 8859-2 (FB); CP1250 (FB); CP852 (FB); CENTEURO (F5); 8859-16 (F8); | |
| found in languages: hu [Hungarian]; | |
| used in romanization of: | |
| uppercase: 0170 |
0xFC
 UTF-8 (c3, bc) Ăź |
name: LATIN SMALL LETTER U WITH DIAERESIS |
| old name: |
|
| Adobe glyph name: udieresis | |
| mnemonic name(s): <u:> | |
| HTML 4 mnemonic name:ü | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 0075 0308 | |
| comment: | |
| found in charsets: 8859-1 (FC); 8859-10 (FC); 8859-13 (FC); 8859-14 (FC); 8859-15 (FC); 8859-2 (FC); 8859-3 (FC); 8859-4 (FC); 8859-9 (FC); CP1250 (FC); CP1252 (FC); CP1254 (FC); CP1256 (FC); CP1257 (FC); CP1258 (FC); CP437 (81); CP775 (81); CP850 (81); CP852 (81); CP857 (81); CP860 (81); CP861 (81); CP863 (81); CP865 (81); ROMAN (9F); CP1116 (81); CP1122 (A1); SAMI_WIN (FC); SAMI_MAC (9F); CENTEURO (9F); 8859-16 (FC); VENTURA_INT (81); |
|
| found in languages: az [Azerbaijani]; bi [Bislama]; br [Breton]; ca [Catalan]; ch [Chamorro]; cy [Welsh]; de [German]; es [Spanish]; et [Estonian]; eu [Basque]; fr [French]; fy [Frisian]; gl [Galician]; hu [Hungarian]; lb [Luxembourgian]; nl [Dutch]; pt [Portuguese]; sl [Slovenian]; sv [Swedish]; tk [Turkmen]; tr [Turkish]; tt [Tatar]; cor [Cornish]; |
|
| used in romanization of: kk_r [Kazakh (cyrillic)]; ky_r [Kyrgyz (cyrillic)]; mn_r [Mongolian (cyrillic)]; tk_r [Turkmen (cyrillic)]; zh_r [Chinese (sino-japanese)]; |
|
| uppercase: 00DC |
0xFD
 UTF-8 (c3, bd) Ă˝ |
name: LATIN SMALL LETTER Y WITH ACUTE |
| old name: |
|
| Adobe glyph name: yacute | |
| mnemonic name(s): <y'> | |
| HTML 4 mnemonic name:ý | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 0079 0301 | |
| comment: | |
| found in charsets: 8859-1 (FD); 8859-10 (FD); 8859-14 (FD); 8859-15 (FD); 8859-2 (FD); CP1250 (FD); CP1252 (FD); CP850 (EC); CP852 (EC); CP861 (98); CP1116 (EC); CP1122 (8D); SAMI_WIN (FD); SAMI_MAC (E0); CENTEURO (F9); |
|
| found in languages: cs [Czech]; cy [Welsh]; da [Danish]; fo [Faroese]; is [Icelandic]; sk [Slovak]; tk [Turkmen]; vi [Vietnamese]; | |
| used in romanization of: el_r [Greek (greek)]; | |
| uppercase: 00DD |
0xFE
 UTF-8 (c5, a3) ĹŁ |
name: LATIN SMALL LETTER T WITH CEDILLA |
| old name: |
|
| Adobe glyph name: tcommaaccent | |
| mnemonic name(s): <t,> | |
| HTML 4 mnemonic name: | |
| category: Ll (Letter, Lowercase) | |
| combining: 0 | |
| decomposition info: 0074 0327 | |
| comment: * | |
| found in charsets: 8859-2 (FE); CP1250 (FE); CP852 (EE); | |
| found in languages: livo [Livonian]; | |
| used in romanization of: ar_r [Arabic (perso-arabic)]; | |
| uppercase: 0162 |
0xFF
 UTF-8 (cb, 99) � |
name: DOT ABOVE |
| old name: |
|
| Adobe glyph name: dotaccent | |
| mnemonic name(s): <'.> | |
| HTML 4 mnemonic name: | |
| category: Sk (Symbol, Modifier) | |
| combining: 0 | |
| decomposition info: <compat> 0020 0307 | |
| comment: Mandarin Chinese light tone | |
| found in charsets: 8859-2 (FF); 8859-3 (FF); 8859-4 (FF); CP1250 (FF); CP1257 (FF); CP852 (FA); ROMAN (FA); | |
| found in languages: | |
| used in romanization of: |
Please send your comments to kiisu@eki.ee
- A hozzászóláshoz be kell jelentkezni